Обучает роботов
Работа выполнена в институте прикладной математики им.М.В.Келдыша РАН при поддержке РФФИ (18-31-20032 мол_а_вед в 2019-2020 годах)
Роботы всё сильнее входят в нашу жизнь. Ещё недавно мы смотрели про них в фантастических фильмах, а сегодня в каждом телефоне есть виртуальный умный ассистент, по квартирам ездят роботы пылесосы, в автомобилях появляются опции автопилота. Сегодня всё это превратилось в реальность. Можно констатировать факт — наступает век умных машин.

Рис. 1. Фантастическое представление о машинном обучении.
Как применяют искусственный интеллект (ИИ) на практике? Ведь уже сейчас применений ИИ в действительности куда больше, чем рисуют даже в фантастических фильмах (рис.1). В действительности ИИ изменил подход к решению проблем в очень многих областях. Основную суть этого подхода можно выразить предельно кратко: если раньше человек долго думал, анализировал и кропотливо создавал/программировал на основе своего опыта некоторую модель для решения определенной проблемы, то ИИ действует иначе. Он работает без какой-то конкретной модели, и его задача состоит в том, чтобы вывести нужную модель/алгоритм внутри себя автоматически, работая только с предоставленными ему данными. Причём в современных подходах человек всё меньше и меньше программирует (рис. 2). Поэтому данные так важны. Данные — это краеугольный камень качественно обученных алгоритмов ИИ, будь то нейронные сети или что-то другое.
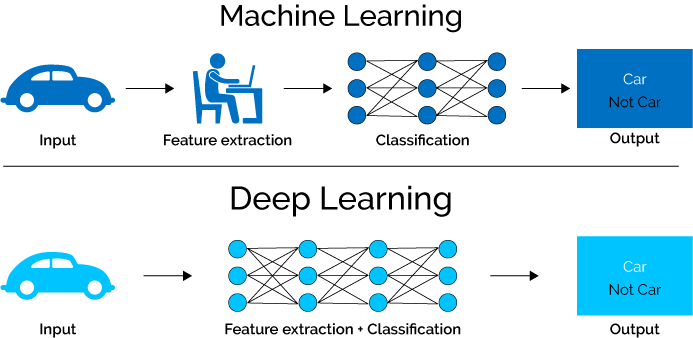
Рис. 2. Обычное и "глубокое" машинное обучение.
Для обучения современных алгоритмов компьютерного зрения требуются наборы данных изображений значительного объема: десятки и сотни тысяч изображений для обучения на статических изображениях, и на порядок больше для анимации. Сбор подобных объемов данных требует определенных технических возможностей и сопряжен со значительными временными и финансовыми затратами. Проблема количества данных также подразумевает необходимость достаточного представления разных объектов (классов), которые должна распознавать целевая модель, т.е. набор данных должен быть сбалансирован относительно представления в нем разных классов. Это может быть трудно достижимо, поскольку определенные классы могут очень редко встречаться в наборах данных реального мира.
Помимо количества данных, важным является и наличие метаинформации о них. Например, в задачах распознавания в компьютерном зрении нужна разметка изображения по классам, на основе которой и будет обучена целевая модель. Разметка большого набора изображений вручную или полуавтоматически может быть затратна. Кроме того, такая разметка часто не имеет необходимой точности, что связано с человеческим фактором и несовершенством средств разметки.
В связи с этим наборы реальных данных, т.е. полученных из реального мира с помощью, например, фото и видеокамер, могут страдать как недостаточным качеством (как самих данных, так и разметки, рис. 3), так и недостаточным количеством.

Рис. 3. Пример некачественной разметки фотографии в размеченных вручную данных.
Но еще большей проблемой является то, что во время проведения исследований специалисты-аналитики должны изменять входные наборы данных для проверки определенных гипотез. А из-за невозможности быстро получить новый набор данных (в связи с упомянутыми выше проблемами) аналитики могут рассматривать только подмножества существующего набора данных, что значительно ограничивает потенциал исследований.
Давайте представим что мы хотим научить автомобильный бортовой компьютер распознавать дорожные знаки, чтобы автомобиль сообщал водителю о превышении скорости, если водитель позволил себе расслабиться 😏.
Нам понадобится много дорожных знаков, в разных ракурсах и с разным освещением. Зимой они могут быть частично или даже полностью покрыты снегом. Также, в реальности знаки могут содержать следы коррозии, повреждений, вандализма или если хотите, быть чьей-то творческой инсталляцией. Всё это реалии нашей жизни с которыми имеет дело каждый водитель и должно быть как-то учтено в процессе обучения.
Получается что каждый знак, должен быть представлен в огромном количестве вариаций. Нужно фотографировать и сортировать фотографии с указанием, где какой знак (рис. 4). Это колоссальный труд и не менее колоссальные финансовые затраты.
Одно из решений заключается в использовании синтетических наборов данных, то есть полученных искусственным путем. В случае изображений — синтезированных с помощью алгоритмов рендеринга. Проблема количества данных может быть решена с помощью алгоритмов настройки и выбора оптических свойств материалов и поверхностей, что позволяет быстро генерировать практически неограниченное количество обучающих примеров с любым распределением классов объектов. Кроме того, можно создавать обучающие примеры, которых очень мало или которые полностью отсутствуют в наборах данных реального мира. Например, аварийные ситуации на дороге или на производстве, боевые действия, объекты существующие только в виде дизайн-проектов или прототипов. Проблема мета-информации при этом решается автоматически — она полностью доступна на этапе генерации данных. Рендер-система создает точные попиксельные маски для разметки изображений по отдельным объектам, а также позволяет получить и другую информацию, такую как: карты глубины, карты нормалей, разметку по материалам поверхности и пр.
На практике конечно не всё так радужно, и несмотря на перечисленные преимущества подхода на основе генерации синтетических наборов данных, при разработке конкретных программных инструментов возникает определенный круг новых проблем.




Рис. 4. Пример дорожных знаков в реальном мире. Природа и человек вносят свой вклад во вшенний вид изначально простых объектов.
Основная проблема заключается непосредственно в генерации контента для 3D-сцен. Вне зависимости от конкретного подхода к генерации, целью которого является создание большого набора разнообразных сцен. Эта цель подразумевает осмысленное размещение объектов в сцене, выбор конкретных 3D-моделей для включения в сгенерированную сцену, установку оптических свойств моделей материалов для объектов на сцене, чтобы они имитировали реальные объекты. Создание 3D-сцен в компьютерной графике на сегодняшний день невозможно без 3D-художников и/или технических художников. Однако для больших наборов данных, создание 3D-сцен вручную практически исключено. Кроме того, существующие инструменты художников не подходят для использования специалистами в области компьютерного зрения. Поэтому необходимо создание инструментов компьютерной графики, ориентированных на прямое применение в области обучения моделей искусственного интеллекта (ИИ). При этом такие инструменты должны являться гибкими и расширяемыми, что позволило бы применять их к широкому кругу задач компьютерного зрения.
Генератор дорожных знаков
К счастью компьютерная графика достигла больших высот реалистичности и мы располагаем физически корректной системой визуализации Hydra Renderer, которую можем встроить в пайплайн нужных нам приложений для решения этой задачи.
Мы создали 3д модели основных форм знаков. Символы взяли из официальных источников, с учётом последних государственных стандартов РФ. (Также эти знаки будут во многом идентичны и для других стран, подписавших Венскую конвенция о дорожных знаках и сигналах.) Далее было создано приложение генерирующее сцену со знаком, в котором случайным образом меняется положение, освещение, накладывается грязь, ржавчина, снег и т.д. Приложение запускало Hydra renderer и на выходе получались тысячи разных знаков (рис. 5).
Рис. 5. Видео демонстрирующее тестирование встраивания знаков в фотографии улиц для отладки и тестирования нейросети.
Как вы могли заметить, дорожные знаки рендерились на фоне реальных фотографий. Дело в том, что перед исследователями, создающими подобные генераторы, на первый план почти всегда выходит один и тот же вопрос — откуда взять контент, который бы выглядел достаточно реалистично. Один из способов, который можно описать выражением “дёшево и сердито” — это дополненная реальность.
Генератор автомобильного движения
Следующая задача является развитием предыдущей. Мы хотим обучить нашу нейросеть находить автомобили или даже самостоятельно ездить.
Мы решали эту задачу в 2 вариантах — с использованием дополненной реальности и без. Идея использования дополненной реальности заключается в том, чтобы сократить затраты на подготовку 3D контента за счёт использования фотографий реального мира. В целом дополненная реальность даёт определённые преимущества, но имеет и серьёзные ограничения:
- Масштабируемость данной группы методов ограничена из-за меньшей вариативности данных в обучающей выборке, чем при обучении только на синтезированных данных за счет ограничения ракурса камеры, и в действительности это является лишь незначительным улучшением по отношению к обучению только на реальных данных.
- Реалистичная дополненная реальность требует реконструкции освещения и окружения, что в некоторых случаях само по себе является нетривиальной задачей.
- Существенным недостатком дополненной реальности является требование автоматического правильного размещения 3D-моделей внутри некоторого реконструированного представления сцены, что в некоторых случаях может быть несложным, (например в нашем случае, поскольку мы размещали автомобили только вдоль дороги), но является фундаментально трудной задачей в общем случае.
К счастью наши первые применения, дорожные знаки и автомобили, были как раз тем случаем когда дополненная реальность работает хорошо: автомобили и знаки размещались вдоль дороги, а условия освещения — преимущество солнечная погода. Что касается окружения, то мы использовали несколько типов HDR панорам для города и пересечённой местности.

Рис. 6. Разметка траекторий на исходных изображениях (слева) и встраивание 3D-моделей на случайные позиции на траекториях (справа).
Итак, мы будем синтезировать машины и встраивать их в фотографии реальных улиц, с реальными автомобилями. Поскольку автомобили, как правило двигаются по дороге, мы приложили определенные усилия чтобы моделировать это.
Здесь нам сильно повезло ещё и потому, что нам помогла группа компьютерного зрения под руководством Антона Конушина из лаборатории компьютерной графики и мультимедиа МГУ, разработав методы сегментации дороги и реконструкции плоскости земли по фотографиям (рис. 1).
Рис. 7. Сгенерированная последовательность с синтезированными автомобилями встроенными в реальные фотографии.
Также, мы можем попробовать полностью смоделировать виртуальный мир, с движением трафика очень похожим на настоящий. Это довольно большая задача, выходящая далеко за рамки наших исследований, поэтому мы использовали готовые инструменты: Autodesk 3ds Max, Building Generator и CityTraffic, для создания контента и самого трафика, выполняя визуализацию в Hydra renderer (рис. 7 и 8).
Рис. 7. Трафик за городом и в городе. Синтезированное видео (без аугментации).
Рис. 8. Пример моделирования записи видео уличной камерой. Синтезированное видео (без аугментации).
Генератор интерьеров
Умными должны быть роботы и для жилых, офисных и складских помещений. Поэтому принципы синтезирования данных нам понадобятся и здесь. Перед исследователями решающими данную проблему, как и в предыдущих примерах, на первый план почти всегда выходит один и тот же вопрос – откуда взять контент, который бы выглядел достаточно реалистично.
Создание и рендеринг интерьеров используются во многих областях компьютерной графики: дизайн, архитектура, игры, виртуальная реальность, кино и обучение искусственного интеллекта. Поэтому задача создания компьютерной программы, умеющей создавать новые интерьеры или хотя бы вариации одного и того же интерьера, актуальна и активно изучается. Создание интерьера можно разделить на 5 основных задач:
- Генерация плана интерьера.
- Создание схемы расположения мебели.
- Создание и настройка 3D контента для наполнения интерьера (мебель, мелкие предметы, люди и т.д.) (рис. 12).
- Последующее наполнение интерьера созданным 3D контентом.
- Обеспечение реалистичности изображения при помощи корректного задания материалов и освещения (рис. 13).
Генерация плана
Создание плана может быть выполнено либо с помощью машинного обучения, либо более традиционными методами, путем создания общего списка размещения комнат, который будет использоваться для случайной сборки результата. При создании плана помещения основную сложность представляет из себя проблема реалистичного размещения комнат: площадь должна быть использована эффективно, т. к. в реальности это сильно влияет на стоимость помещения. Поэтому относительно простые методы на основе тайлов, хорошо подходящие для генерации подземелий в компьютерных играх, здесь могут быть неприменимы. Кроме того, таловые методы в чистом виде очень сильно ограничены в вариативности получаемого результата, что плохо для обучения искусственного интеллекта.
Мы использовали метод с комбинацией методов «плотной упаковки» и «изнанки», поскольку для нас было в первую очередь важно сделать генератор контролируемым. Например, если пользователь хочет получить помещение с длинными коридорами и/или одной большой комнатой посередине, мы должны это учитывать. Внешняя форма здания или многоэтажность при этом нас интересуют в меньшей степени (рис. 9).
Расстановка мебели
В ранних работах, исследующих проблему автоматического размещения мебели в интерьерах, используются простые статистические отношения между объектами. Следующим шагом был синтез сцены с использованием машинного обучения. Поскольку в практике обучения нейросетей важно иметь возможность генерировать выборки с заданным распределением и типами объектов, мы не использовали методы на основе машинного обучения, которые будут расставлять предметы так, как это было в исходных обучающих выборках. Нам было важно разработать контролируемый 3D художником метод, который бы в то же время умел воспроизводить строго определённое положение мебели для одного и того же зерна генератора случайных чисел. Это важно, поскольку позволяет пользователям проверять различные гипотезы за счёт генерации специфических выборок изображений. Например: (1) выборки где изменялось положение мебели но не изменялись сами 3D модели, (2) выборки где изменялись 3D модели, но не изменилось их положение. Поэтому расстановка мебели по некоторому шаблону с использованием настраиваемых статистических соотношений больше подходит для нашей цели.
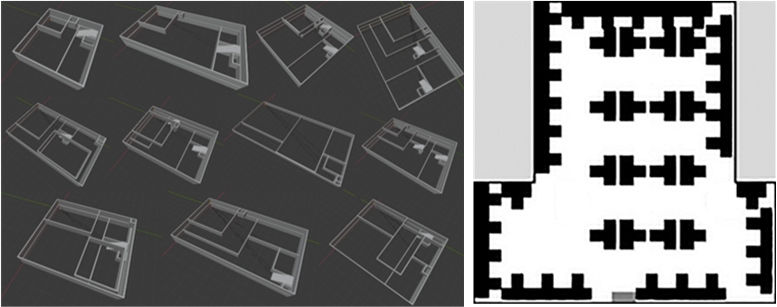
Рис. 9. Демонстрация 3D моделей сгенерированных планов помещений (слева) и демонстрация алгоритма размещения мебели по шаблону (справа).
Размещение мелких объектов
Для размещения объектов на столах мы также использовали шаблонный метод. Проведя несколько экспериментов с физическим моделированием в начале нашего проекта, мы обнаружили, что на практике с его помощью чрезвычайно трудно добиться адекватного и воспроизводимого результата: объекты сваливались в кучу, проваливались под стол или находились в невозможных конфигурациях (книга на клавиатуре, мышка на мониторе, системный блок по центру на столе и т.п.).
Мы остановились на подходе, когда художник подготовил несколько шаблонов с настроенными ограничивающими рамками и углами поворота для каждого типа объекта на столе или на поверхности пола: монитор, системный блок, клавиатура и др. (рис. 10). Если в плоскости стола происходит столкновение объектов, мы применяем правило «чистой доски», очищая всё и заново регенерируя до тех пор, пока не исчезнут столкновения. Это гарантирует, что полученное распределение объектов будет такое же, как и при использовании физической симуляции.

Рис. 10. Демонстрация автоматической расстановки предметов по шаблону.
Материалы и освещение
Эта задача сводится к корректной рандомизации материалов и текстур. Простая рандомизация в этом случае плохая идея, потому что в реальности объекты разделены на классы и например мы не можем назначить текстуру деревянного паркета на кожаную сумку. Таким образом, нам нужно разбить все объекты на классы, чтобы ограничить рандомизацию. Также есть классы объектов имеющих уникальные материалы и текстуры, например картины или подавляющее большинство корпусов компьютерной техники, имеющих чёрный цвет.
Для того чтобы 3d художник мог настраивать рандомизированный контент, мы разработали специализированный плагин материала позволяющий выбирать классы материалов, настраивать распределение и осуществлять предпросмотр работы генератора на различных 3d моделях из базы (рис. 11). База 3d моделей была собрана нами из открытых источников. Для каждой 3d модели, 3d художник вручную назначал рандомизированный материал для отдельных частей, указывая классы материалов и прочие настройки.

Рис. 11. Скриншот разработанного нами специализированного редактора материалов. В левой части расположен выбор классов материалов, если объект может иметь любой материал из выбранных классов. Ниже расположен параметр “Target”, игнорирующий общие классы материалов и имеющий свой, уникальный класс материалов. Например пол, стена, картина, экран телевизора и т.д. Это позволяет более точно и корректно рандомизировать объекты. Справа находятся настройки распределений для дополнительной рандомизации параметров.
Рис. 12. Демонстрация предпросмотра работы рандомизатора материалов на 3D моделях из базы.
Рис. 13. Примеры синтезированных изображений сгенерированных интерьеров, полученных при помощи разработанной системы. Маленькое цветное изображение в правом нижнем углу — маска идентификаторов объектов.
Рандомизация текстур
Текстуры — важнейший компонент синтеза реалистичных изображений. Для задач обучения нейронных сетей было бы не плохо уметь их рандомизировать, при этом сохраняя отличительные черты и характер исходной текстуры. Мы создали такой генератор. Он создаёт бесшовные текстуры на основе текстуры оригинала, в неограниченном количестве. Также, к генерируемым текстурам можно применять стиль из другой текстуры, это придаст им дополнительный характер.
Рис. 14. Примеры сгенерированных текстур.
Заключение
Как мы видим, синтетические данные это хорошее дополнение к реальным данным улучшающее обучение сетей, а в некоторых случаях и вовсе их главный источник.
Генерация рандомизированного реалистичного 3D контента для обучения нейронных сетей с высокой вариативностью является комплексной задачей, в которой нельзя выделить какое-то одно узкое место. Главное требование для подобной системы — развитая инфраструктура, позволяющая быстро и легко компоновать результаты работы различных алгоритмов и фреймворков вместе, осуществлять быстрое прототипирование и настройку алгоритмов генерации. А главное требование к рендер-системе — автоматизированная настройка материалов, подвергающихся рандомизации, и непосредственная связь с базой используемых генератором 3D моделей.
Это является сильной стороной нашего решения, так что если вы собираетесь обучать искусственный интеллект при помощи рендеринга, пишите нам и Гидра Вам поможет!
Работа выполнена в институте прикладной математики им.М.В.Келдыша РАН при поддержке РФФИ (18-31-20032 мол_а_вед в 2019-2020 годах).
© Ray Tracing Systems. 2014-2021. Все права защищены.